

Prvky modelu relačnej databázy, ako to urobiť, príklad
- 2749
- 22
- Alan Milota
On Relačný model databáz Je to metóda na štruktúrovanie údajov pomocou vzťahov prostredníctvom štruktúr s mriežkou, ktoré pozostávajú zo stĺpcov a riadkov. Je to koncepčný princíp relačných databáz. Navrhol Edgar F. Codd v roku 1969.
Odvtedy sa stal dominantným databázovým modelom pre komerčné aplikácie, v porovnaní s inými databázovými modelmi, ako sú hierarchické, sieťové a objekty.
Zdroj: Pixabay.com Codd netušil o mimoriadne dôležitých a vplyvných, čo by bola jeho práca ako platforma pre relačné databázy. Väčšina ľudí pozná fyzické vyjadrenie vzťahu v databáze: tabuľka.
Relačný model je definovaný ako databáza, ktorá umožňuje zoskupenie svojich dátových prvkov do jednej alebo viacerých nezávislých tabuliek, ktoré môžu navzájom súvisieť pomocou spoločných polí do každej súvisiacej tabuľky.
[TOC]
Databázová správa
Databáza je podobná tabuľke. Vzťahy, ktoré je možné vytvoriť medzi tabuľkami.
Účelom relačného modelu je poskytnúť deklaratívnu metódu na špecifikáciu údajov a konzultácií: používatelia priamo deklarujú, aké informácie databáza obsahuje a aké informácie od nej chcete.
Na druhej strane umožňujú, aby bol softvér systému správy databáz zodpovedný za opis dátových štruktúr na ukladanie a postup regenerácie na reagovanie.
Väčšina relačných databáz používa jazyk SQL na konzultáciu a definíciu údajov. V súčasnosti existuje mnoho systémov riadenia relačných databáz alebo RDBMS (systém správy relačných databáz), ako sú Oracle, IBM DB2 a Microsoft SQL Server.
Charakteristiky a prvky
- Všetky údaje sú koncepčne znázornené ako usporiadané dispozície údajov v riadkoch a stĺpcoch, nazývané vzťahy alebo tabuľka.
- Každá tabuľka musí mať hlavičku a telo. Zadanie je jednoducho zoznam stĺpcov. Telo je sada údajov, ktoré vyplňujú tabuľku usporiadané v riadkoch.
- Všetky hodnoty sú výstupy. To znamená, že v ktorejkoľvek danej polohe riadku/stĺpca v tabuľke je iba jedna jedinečná hodnota.
-Predmety
Nasledujúci obrázok zobrazuje tabuľku s názvami jej základných prvkov, ktoré tvoria úplnú štruktúru.
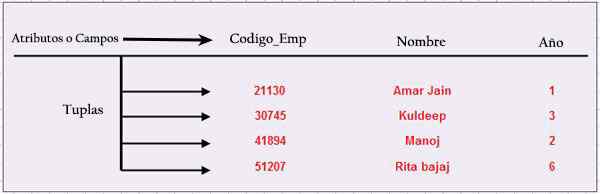
Tupla
Každý riadok údajov je tupla, známa tiež ako registrácia. Každý riadok je n-tupla, ale „n-“ je všeobecne vylúčené.
Stĺp
Každý stĺpec tupla sa nazýva atribút alebo pole. Stĺpec predstavuje množinu hodnôt, ktoré môže mať konkrétny atribút.
Podtužovať
Každý riadok má jeden alebo viac stĺpcov nazývaný tabuľka. Táto kombinovaná hodnota je jedinečná pre všetky riadky tabuľky. Prostredníctvom tohto kľúču bude každý tupla identifikovaný jednoznačným spôsobom. To znamená, že kľúč sa nedá duplikovať. Nazýva sa to primárny kľúč.
Na druhej strane, externý alebo sekundárny kľúč je pole tabuľky, ktorá sa týka primárneho kľúču inej tabuľky. Používa sa na odkaz na primárnu tabuľku.
-Pravidlá integrity
Pri navrhovaní relačného modelu sa definujú niektoré podmienky, ktoré sa musia splniť v databáze, nazývané pravidlá integrity.
Môže vám slúžiť: makrocomputery: História, charakteristiky, použitia, príkladyKľúčová integrita
Primárny kľúč musí byť jedinečný pre všetky n -tice a nemôže mať nulovú hodnotu (null). V opačnom prípade nebudete schopní výlučne identifikovať riadok.
Pre kľúč zložený z niekoľkých stĺpcov, žiadny z týchto stĺpcov nemôže obsahovať null.
Referenčná integrita
Každá hodnota externého kľúča sa musí zhodovať s hodnotou primárneho kľúča v referenčnej alebo primárnej tabuľke.
V sekundárnej tabuľke je možné s externým kľúčom vložiť iba jeden riadok, ak táto hodnota existuje v primárnej tabuľke.
Ak sa hodnota kľúča zmení v primárnej tabuľke, na aktualizáciu alebo elimináciu riadku, potom sa musia všetky riadky v sekundárnych tabuľkách s týmto externým kľúčom aktualizovať alebo eliminovať.
Ako vytvoriť vzťahový model?
-Zbierať dáta
Musia sa zhromaždiť potrebné údaje na ich uloženie do databázy. Tieto údaje sú rozdelené do rôznych tabuliek.
Pre každý stĺpec sa musí zvoliť príslušný typ údajov. Napríklad: celé čísla, čísla s pohyblivou rádovou čiarkou, text, dátum atď.
-Definujte primárne kľúče
Pre každú tabuľku musíte vybrať stĺpec (alebo niekoľko stĺpcov) ako primárny kľúč, ktorý jedinečne identifikuje každý riadok tabuľky. Primárny kľúč sa používa aj na označenie iných tabuliek.
-Vytvárajte vzťahy medzi tabuľkami
Databáza pozostávajúca z nezávislých a nesúvisiacich tabuliek má malý účel.
Najdôležitejším aspektom pri návrhu relačnej databázy je identifikovať vzťahy medzi tabuľkami. Typy vzťahov sú:
Jeden do mnohých
V databáze „triedy“ môže učiteľ učiť v nulových alebo viacerých triedach, zatiaľ čo triedu vyučuje jeden učiteľ. Tento typ vzťahu je známy ako jeden pre mnohých.
Tento vzťah nemôže byť zastúpený v jednej tabuľke. V databáze „Zoznam tried“ môžete mať tabuľku s názvom Učitelia, ktorá ukladá informácie o učiteľoch.
Na ukladanie tried, ktoré vyučuje každý učiteľ.
Na druhej strane, ak máte tabuľku s názvom triedy, ukladá informácie o triede, na ukladanie informácií o učiteľovi by mohli vytvoriť ďalšie stĺpce.
Avšak, ako učiteľ môže učiť v mnohých triedach, jeho údaje by sa zdvojnásobili v mnohých radoch v tabuľke triedy.
Navrhnite dva tabuľky
Preto je potrebné navrhnúť dve tabuľky: tabuľka tried na ukladanie informácií o triedach, s triedou_id ako hlavným kľúčom a hlavnou tabuľkou na ukladanie informácií o učiteľoch, s učiteľom_id ako hlavným kľúčom.
Potom môžete vytvoriť vzťah jeden k mnohým ukladaním primárneho kľúča hlavnej tabuľky (Master_ID) v tabuľke tried, ako je znázornené nižšie.
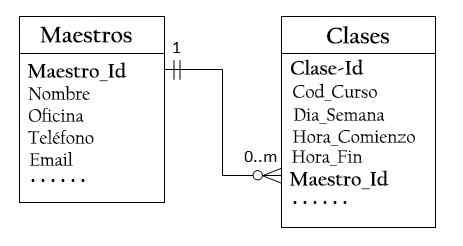
Stĺpec Master_id v tabuľke tried je známy ako externý alebo sekundárny kľúč.
Pre každú hodnotu Master_id v hlavnej tabuľke môže byť v tabuľke tried nula alebo viac riadkov. Pre každú hodnotu class_id v tabuľke tried je v hlavnej tabuľke iba jeden riadok.
Mnohým
V databáze „predaja produktov“ môže objednávka zákazníka obsahovať niekoľko produktov a produkt sa môže objaviť v niekoľkých objednávkach. Tento typ vzťahu je pre mnohých známy ako mnohí.
Môže vám slúžiť: IKT (informačné a komunikačné technológie)Môžete spustiť databázu „predaja produktov“ s dvoma tabuľkami: produkty a objednávky. Tabuľka výrobkov obsahuje informácie o výrobkoch, s produktom ako primárnym kľúčom.
Na druhej strane objednávky obsahujú zákaznícke objednávky a požadujú primárny kód.
Nemôžete uložiť požadované výrobky v objednávkovej tabuľke, pretože nie je známe, koľko stĺpcov rezervuje pre výrobky. Z rovnakého dôvodu nemôžu byť v tabuľkovom produktoch uložené ani objednávky.
Ak chcete pripustiť vzťah mnohým mnohým, je potrebné vytvoriť tretiu tabuľku, známu ako tabuľka Únie (žiada), kde každý riadok predstavuje prvok konkrétneho príkazu.
Pre požadujúcu tabuľku sa primárny kľúč pozostáva z dvoch stĺpcov: objednávok a produkt, identifikácia každého riadku v každom riadku.
Požadované a produktové stĺpce v žiadosti o metódy sa používajú na odkazy na objednávky a výrobky. Preto sú tiež externými kľúčmi k žiadosti o žiadosť.
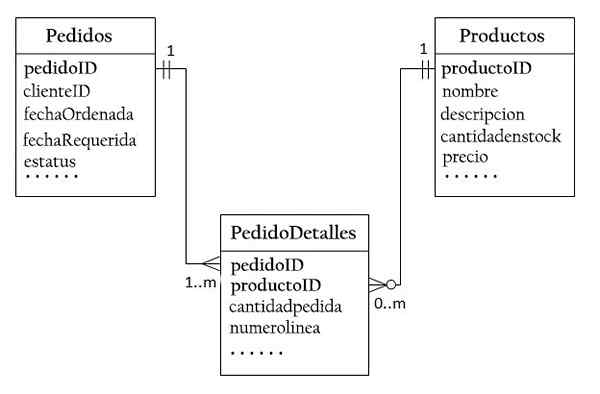
Jeden za druhým
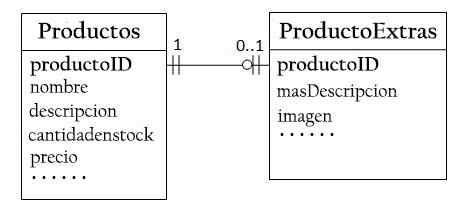
V databáze „predaja produktov“ môže mať produkt voliteľné informácie, ako ďalší popis a jeho obraz. Udržujte ho vo vnútri výrobkov, ktoré by generovalo veľa prázdnych priestorov.
Preto môžete vytvoriť ďalšiu tabuľku (produkt Extexts) na ukladanie voliteľných údajov. Vytvorí sa iba záznam pre produkty s voliteľnými údajmi.
Tieto dve tabuľky, výrobky a produkt majú vzťah jeden -do -One. Pre každý riadok v tabuľke produktu je v tabuľkách produktu maximálny riadok. Rovnaký produkt by sa mal použiť ako hlavný kľúč pre obe tabuľky.
Výhody
Štrukturálna nezávislosť
V modeli relačnej databázy zmeny v štruktúre databázy neovplyvňujú prístup k údajom.
Ak je možné vykonať zmeny v štruktúre databázy bez toho, aby ovplyvnilo schopnosť DBMS prístup k údajom, je možné povedať, že sa dosiahla štrukturálna nezávislosť.
Koncepčná jednoduchosť
Model relačnej databázy je ešte jednoduchší na koncepčnej úrovni ako hierarchický model alebo databázová sieť.
Pretože model relačnej databázy uvoľňuje návrhára z detailov fyzického ukladania údajov, dizajnéri sa môžu sústrediť na logický pohľad na databázu.
Ľahký dizajn, implementácia, údržba a používanie
Model relačnej databázy dosahuje nezávislosť údajov a nezávislosť štruktúry, ktorá uľahčuje návrh, údržbu, správu a používanie databázy oveľa ľahšie ako ostatné modely.
Konzultačná kapacita ad-hoc
Prítomnosť veľmi výkonnej, flexibilnej a ľahkej konzultačnej kapacity je jedným z hlavných dôvodov obrovskej popularity modelu relačnej základne databázy.
Konzultačný jazyk modelu relačnej databázy, nazývaný štruktúrovaný konzultačný jazyk alebo SQL, sa splnia ad-hoc dotazy. SQL je jazyk štvrtej generácie (4GL).
4GL umožňuje používateľovi určiť, čo by sa malo urobiť, bez toho, aby sa malo uviesť. Užívatelia SQL teda môžu určiť, aké informácie chcú, a zanechať podrobnosti o tom, ako získať informácie do databázy.
Nevýhody
Hardvérové náklady
Model relačnej databázy skrýva zložitosť jej implementácie a podrobnosti o fyzickom ukladaní používateľských údajov.
Môže vám slúžiť: Aké sú g kódy? (S príkladom)Na tento účel potrebujú relačné databázové systémy počítače s výkonnejším hardvérom a úložiskom.
Preto RDBMS potrebuje výkonné stroje na prácu bez problémov. Keďže však spracovacia sila moderných počítačov rastie exponenciálnym tempom, potreba väčšieho výkonu spracovania v súčasnom scenári už nie je veľmi veľkým problémom.
Ľahkosť dizajnu môže viesť k zlému dizajnu
Relačná databáza sa dá ľahko navrhnúť a používať. Používatelia nepotrebujú poznať zložité podrobnosti o fyzickom ukladaní údajov. Nepotrebujú vedieť, ako sú údaje skutočne uložené na prístup k nim.
Tento návrh a použitie jednoduchosti môže viesť k vývoju a implementácii veľmi zle navrhnutých systémov na správu databáz. Pretože databáza je efektívna, tieto neefektívnosti dizajnu sa neobjaví, keď je navrhovaná databáza a keď existuje iba malé množstvo údajov.
Ako databáza rastie, zle navrhnuté databázy spomaľujú systém a spôsobia degradáciu výkonu a korupcie údajov.
Fenomén „informačných ostrovov“
Ako už bolo povedané, relačné databázové systémy sa dajú ľahko implementovať a používať. Tým sa vytvorí situácia, v ktorej príliš veľa ľudí alebo oddelení vytvorí svoje vlastné databázy a aplikácie.
Tieto informačné ostrovy sa vyhnú integrácii informácií, ktoré sú nevyhnutné pre tekuté a efektívne fungovanie organizácie.
Tieto jednotlivé databázy tiež spôsobia problémy, ako sú nekonzistentnosť údajov, duplikácia údajov, redundancia údajov atď.
Príklad
Predpokladajme, že databáza pozostávajúca z predbežných tabuliek, kusov a zásielok. Štruktúra tabuliek a niektoré vzorové záznamy sú uvedené nižšie:
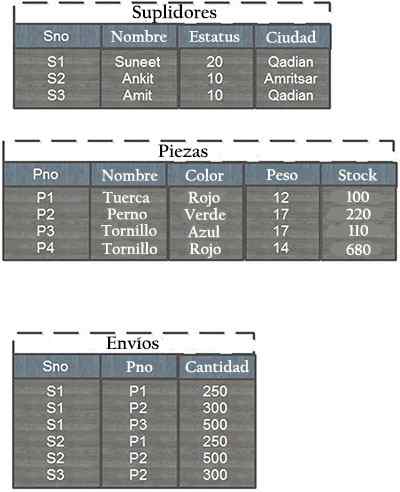
Každý riadok v dodávateľskej tabuľke je identifikovaný jedinečným číslom dodávateľa (SNO), ktorý jedinečne identifikuje každý riadok tabuľky. Podobne má každý kus jedinečné číslo dielu (PNO).
Okrem toho v prepravnej tabuľke nemôže existovať viac ako jedna zásielka pre danú kombináciu dodávateľa / kusov, pretože táto kombinácia je hlavným prepravným kľúčom, ktorý slúži ako tabuľka Únie, pretože mnohí sú vzťahom k mnohým k mnohým.
Vzťah tabuliek a zásielok je uvedený spoločným poľom PNO (číslo kusu) a vzťah medzi dodávateľmi a zásielkami vyplýva z spoločného poľa SNO (číslo dodávateľa).
Analýza tabuľky zásielok je možné získať ako informácie, ktoré sa odosielajú celkom 500 orechov od dodávateľov Suneet a Ankit, každý 250.
Podobne boli poslané 1.Celkovo 100 skrutiek od troch rôznych dodávateľov. Z dodávateľa Suneet bolo odoslaných 500 modrých skrutiek. Neexistujú žiadne zásielky červenej skrutky.
Odkazy
- Wikipedia, The Free Encyclopedia (2019). Relačný model. Prevzaté z: v.Wikipedia.orgán.
- Ravepedia (2019). Relačný model. Prevzaté z: ravepedia.com.
- Diesh Thakur (2019). Relačný model. Poznámky k elektronickému zariadeniu. Zobraté z: Ekomputernotes.com.
- Geeks for Geeks (2019). Relačný model. Prevzaté z: Geeksforgeeks.orgán.
- Technologická univerzita Nanyang (2019). Výukový program rýchleho skla. Prevzaté z: NTU.Edu.SG.
- Adrienne Watt (2019). Kapitola 7 Vzťahový dátový model. BC Otvorte učebnice. Zobraté z: OpenTextBC.Ac.
- Toppr (2019). Relačné databázy a schémy. Prevzaté z: Toppr.com.
- « Operations Research, pre čo ide, modely, aplikácie
- Vanadio História, vlastnosti, štruktúra, použitie »